Lasse Schultebraucks IT Consultant
The Problem of overfitting and underitting
This blog post is part of a series, where I talk about concepts and algorithms in Machine Learning.
In this part I want to talk about Overfitting and Underfitting, which are common problems in Machine Learning which lead to low pThis blog post is part of a series, where I talk about concepts and algorithms in Machine Learning.\nIn this part I want to talk about Overfitting and Underfitting, which are common problems in Machine Learning which lead to low predictive models e.g. in classification problems.\nOverfitting\nOverfitting often happens when your train your model with too much data. Then the model learn from the noise and inaccurate data entries from the data set. If the model then should predict the target of the new data, it does not categorize the data correct, because there is too much noise and details. Overfitting often happens with non-parametric and non-linear methods, because this types of machine learning algorithms have more freedom in building a model based on the data set and therefore these types of algorithms can really build unrealistic models. A solution to avoid overfitting is using a linear algorithm like Support Vector Machines (SVM) if you have linear data or using parametersredictive models e.g. in classification problems.
Overfitting
Overfitting often happens when your train your model with too much data. Then the model learn from the noise and inaccurate data entries from the data set. If the model then should predict the target of the new data, it does not categorize the data correct, because there is too much noise and details. Overfitting often happens with non-parametric and non-linear methods, because this types of machine learning algorithms have more freedom in building a model based on the data set and therefore these types of algorithms can really build unrealistic models. A solution to avoid overfitting is using a linear algorithm like Support Vector Machines (SVM) if you have linear data or using parameters like the maximal depth if you are using decision trees.
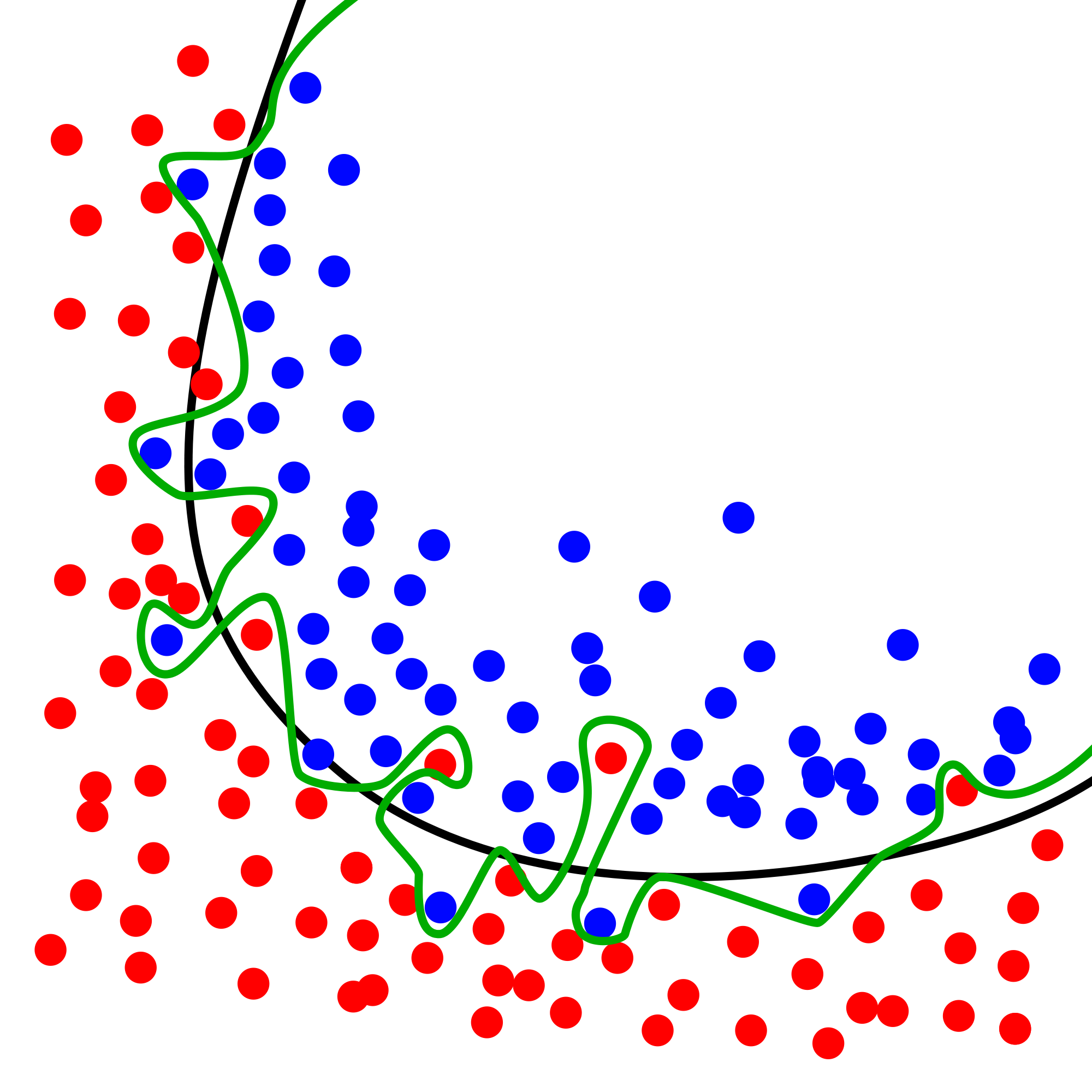
In the example above we can see lines of an overfitted model an a line of a model with a regular model. The green line is from the overfitted model. It is very complex and overreacts for every point instead of just finding a moderate way like the black line from the regular model.
Underfitting
Underfitting is obviously the opposite of underfitting, but also can destroy the accuracy of your machine learning model. If often happens when you have to less data to build an accurate model. It also happens when you try to build a linear model with non-linear data. Then the rules of your machine learning model are to easy and flex and the model will probably guess a lot of wrong predictions. Solutions for underfitting beside getting more data is e.g. feature engineering, so e.g. reducing the features by feature selection.
Choosing the wrong parameters
Further overfitting and underfitting appears if you choosing the wrong parameters of your machine learning algorithms. As mentioned above, decision trees have e.g. the parameter max depth, which describes the max depth of the tree. If max depth is to high, overfitting will be encouraged and if max depth is to low, underfitting will be a problem.
In the next weeks I will post a blog post where I talk about concept on how you can avoid building a overfitted or underfitted machine learning model.
Resume
So overfitting and underfitting are both things you want to avoid, in the best case you want to be in the middle of them. To avoid both, be care to have enough data (there can’t be too much data, but you then have to care about choosing the right parameters and the right algorithms) and carefully evaluate your data set to choose the right decision for training.
Written on October 2nd , 2017 by Lasse Schultebraucks